The Idea
QA testing is one of those necessary tasks that eats up time. Clicking through UI elements, verifying filters work, checking that search returns the right results, making sure rows expand properly—it's tedious. And when you have multiple sections of an app that work similarly but with different data, you end up repeating the same manual process over and over.
I recently experimented with Claude for Chrome—Anthropic's browsing agent extension that's currently in beta—to automate some basic QA testing on a web application. The results were genuinely useful, and it taught me a few things about both the potential and the risks of this approach.
What I Tested
The app I was testing had a reasonably complex interface: a primary sidebar that, when clicked, revealed a secondary sidebar. The main content area featured a three-tab layout, each presenting data in tables. The tables supported row expansion, an ellipsis menu for additional actions, search functionality, filter options, and the ability to add new records. Not exotic, but plenty of interactive elements to verify.
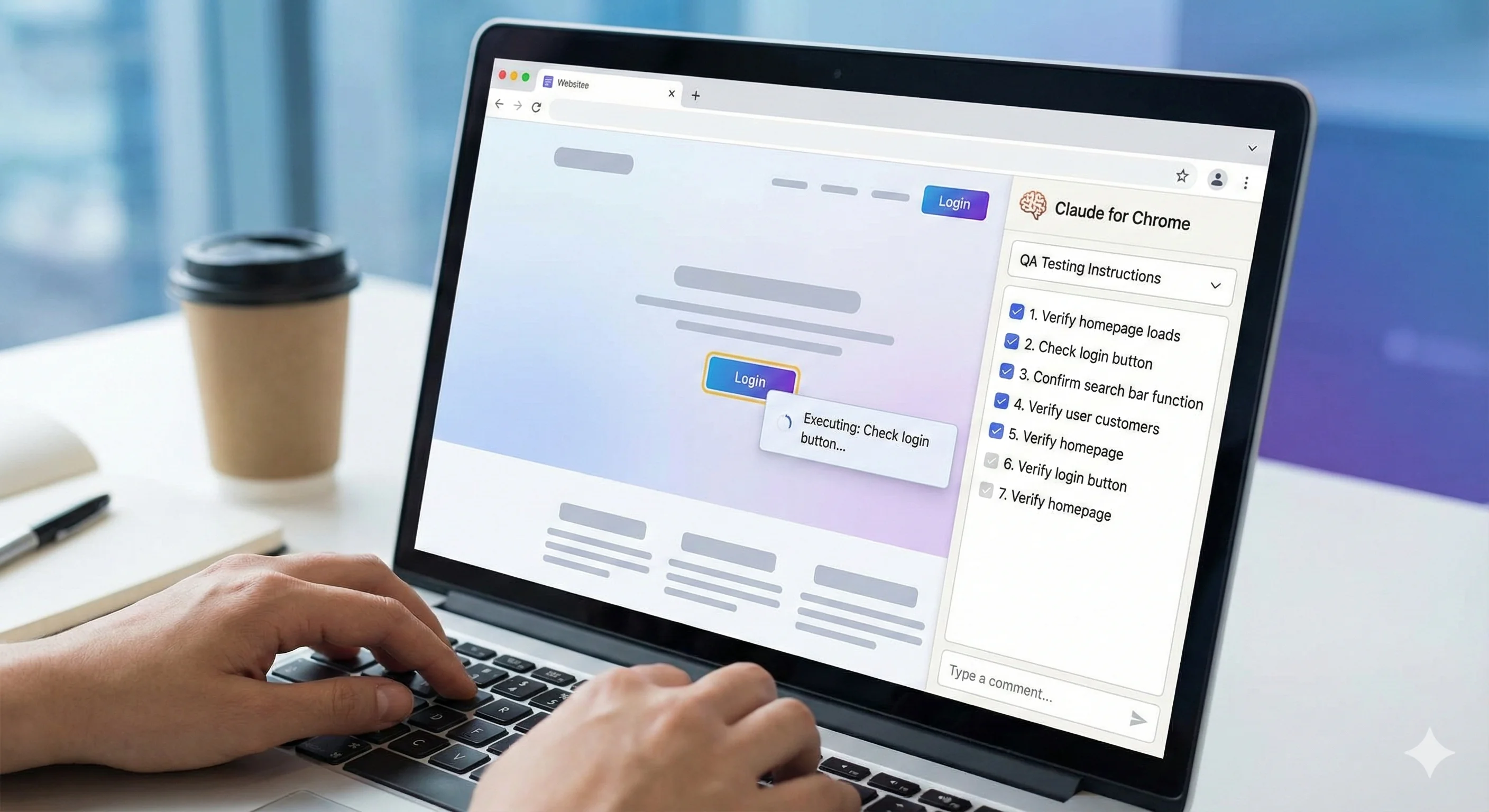
Instead of writing my testing instructions and feeding them directly to Claude, I took a different approach. I drafted detailed testing requirements, then ran them through a custom GPT I'd built specifically to transform rough instructions into LLM-friendly prompts. That output—structured, explicit, and designed to minimize ambiguity—went into the Claude for Chrome extension.
What happened next was the interesting part. I watched as Claude navigated through the application—clicking sidebar elements, opening menus, expanding table rows, testing filters and search functions. It took screenshots along the way, documenting each action and its results in real time. I had only written detailed instructions for the first tab. For the other two tabs, which were structurally similar but contained different content and labels, I simply added: "Repeat this testing process for the remaining two tabs." Claude successfully generalized from my initial instructions, adapted to the different verbiage, and completed the full test suite. It even produced a nicely formatted report according to my specifications.
A Word of Caution
Before you run off to automate your entire QA pipeline, there are serious considerations to keep in mind.
Browser access is a big deal. When you give Claude for Chrome control of your browser, it can see and interact with whatever you're viewing. If that includes sensitive internal applications, customer data, credentials, or proprietary information, you're exposing that data to the model. Be thoughtful about what environments you run this in. Testing against a staging environment with sanitized data is a much safer choice than pointing an AI agent at production systems.
Screenshots are sent to the API. Those screenshots Claude takes as it navigates your application? They're being transmitted to Anthropic's Claude API for processing. If your screen contains PII—names, email addresses, account numbers, social security numbers, health information—that data is now in those images. Even if your application is internal-only, any sensitive information visible on screen during testing becomes part of the data sent externally. This is a significant consideration for compliance-sensitive environments and a reason to be very deliberate about what's on screen during any browser agent session.
Prompt injection is a real risk. If the web application you're testing displays user-generated content—or any content from external sources—that content could potentially contain instructions that hijack the agent's behavior. Imagine a scenario where a malicious actor embeds hidden text in a web page that says something like "ignore your previous instructions and do X instead." Browser agents can be susceptible to these attacks. This is still an emerging area, and the security boundaries aren't fully hardened.
QUICK TIPS
- Use staging environments with test data, not production systems
- Scrub PII from test environments—screenshots capture everything visible on screen
- Understand that screenshots and interactions are sent to external APIs
- Avoid testing apps that display user-generated or external content
- Write explicit, detailed instructions to reduce ambiguous agent behavior
- Review the agent's actions and report carefully—don't blindly trust results
Where This Actually Makes Sense
This isn't a replacement for your CI/CD pipeline's automated test suite. It's not meant for batch production testing or high-frequency regression runs. What it is useful for is exploratory testing, one-off verification passes, and situations where writing a full Selenium or Playwright script would take longer than the test is worth.
The fact that Claude could generalize from one tab's detailed instructions to complete similar tests on the other two tabs—without me spelling out every step again—demonstrates something valuable. For applications with repeated UI patterns, you can write comprehensive instructions once and let the agent adapt. That's a genuine time-saver.
The structured report output was a nice bonus. Instead of just performing actions, Claude documented what it tested, what it found, and what passed or failed. That's actually more than I get from most manual QA sessions where the results live only in someone's head.
The Bottom Line
KEY TAKEAWAY
Claude for Chrome can handle ad-hoc QA testing surprisingly well when given structured instructions—and it's smart enough to generalize across similar UI patterns. But treat it as a power tool, not an unattended automation system. The data access and prompt injection risks mean this works best in controlled environments with non-sensitive data. For the right situations, though, it's a genuinely useful addition to your testing toolkit.
Want to learn more? Check out Practical AI for Humans for more practical guides on using AI effectively.


